



Introduction
The reinforcement learning technique has shown remarkable effectiveness in training agents to execute challenging tasks in diverse settings. As difficulties escalate and situations become increasingly complex, conventional reinforcement learning methods might face obstacles in discovering ideal answers rapidly. HRL promises to provide a viable solution by dismantling complex tasks into more straightforward sub-objectives.
In this piece, we venture into the HRL domain and analyze the Options-Critic framework, a widely recognized method that incorporates tabular Q-Learning with hierarchical policies. Understanding HRL by constructing a customizable framework in a minimal setting fosters comprehension of its capabilities.
Understanding Hierarchical Reinforcement Learning
HRL leverages the way humans naturally decompose tasks to solve complex issues. In software development, modular functions help us attain particular objectives. Similarly, HRL splits complicated decisions over extended timeframes into more tractable sub-processes. Different levels of policies address distinct responsibilities, with top-level policies overseeing more ambitious targets.,
Envision an agent needing to tidy and organize a dining table. The agent’s primary objective is to acknowledge and arrange dinnerware., Achieving accurate object handling requires the integration of arm, hand, and finger movements., With HRL, the agent can develop practical policies across multiple levels, resulting in faster learning and better choices.,
The Options-Critic Framework: Architecture and Benefits
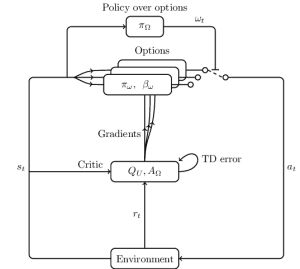
HRL often utilizes the Option-Critic framework. In this framework, the agent’s decision-making process involves two main components: the Option section and the Critique portion. The meta-policy and termination policy within the Option section jointly determine the lower-level policies. While the Policy part outlines options, the Critic component provides analysis and feedback.,
The Options-Critic structure facilitates training and exploration with numerous advantages. Shorter episode lengths due to high-level policies enable quicker reward propagation and better learning. Exploring at a higher echelon offers the agent a richer comprehension of the circumstances, allowing it to adopt wiser measures than it would through minute-level undertakings.
Policy development for Higher and Lower Levels
These policies are essential for implementing Options-Critic The 2D Q-table of Q_Omega features each state’s selection of options influencing the lower-level policy’s actions. Epsilon-greedy sampling determines which options will be chosen.
Softmax probabilities guide action selection within Q_U’s lower-level policy. The policy’s instructions are executed through the agency of this component., The termination policy outlines when to change to another approach.
The Role of the Critic: Evaluating Options
The Critic module within the Options-Critic structure examines the alternatives proposed by the more elevated meta-policy. The evaluation offers valuable inputs for the agent to make better decisions., The Critic incorporates elements of the Actor-Critic framework, such that Q_Omega and Q_U comprise the Option branch, and Q_U’s worth impacts the Critic.,
Reinforcement Learning Agent Training and Performance Metrics
The agent will be trained and tested within a 2D four-room environment in this section. The training and testing stages involve creating a Colab notebook. While training, the meta-policy (Q_Omega) acquires options and termination tactics, which are later employed during evaluation to steer the subordinate policy’s movements. By modifying the objective every 1000 episodes, agent performance experiences a noteworthy boost owing to the contextualized decision-making process.
Conclusion
This framework enables efficient solution of complicated challenges via hierarchical Reinforcement Learning., Breaking down duties into smaller chunks and using numerous policy tiers enables agents to make better choices. The Options-Critic framework offers promising opportunities for AI utilization in multiple realms, from robotics to natural language processing, where extended-horizon determination making is vital. Future innovations in HRL will likely deliver AI with heightened capacities.





